MEDFAIR: benchmarking fairness for medical imaging
Yongshuo Zong, Yongxin Yang, and Timothy Hospedales
ICLR, 2023
TL;DR: We develop a fairness benchmark for medical imaging and find that the state-of-the-art bias mitigation algorithm does not significantly outperform ERM.
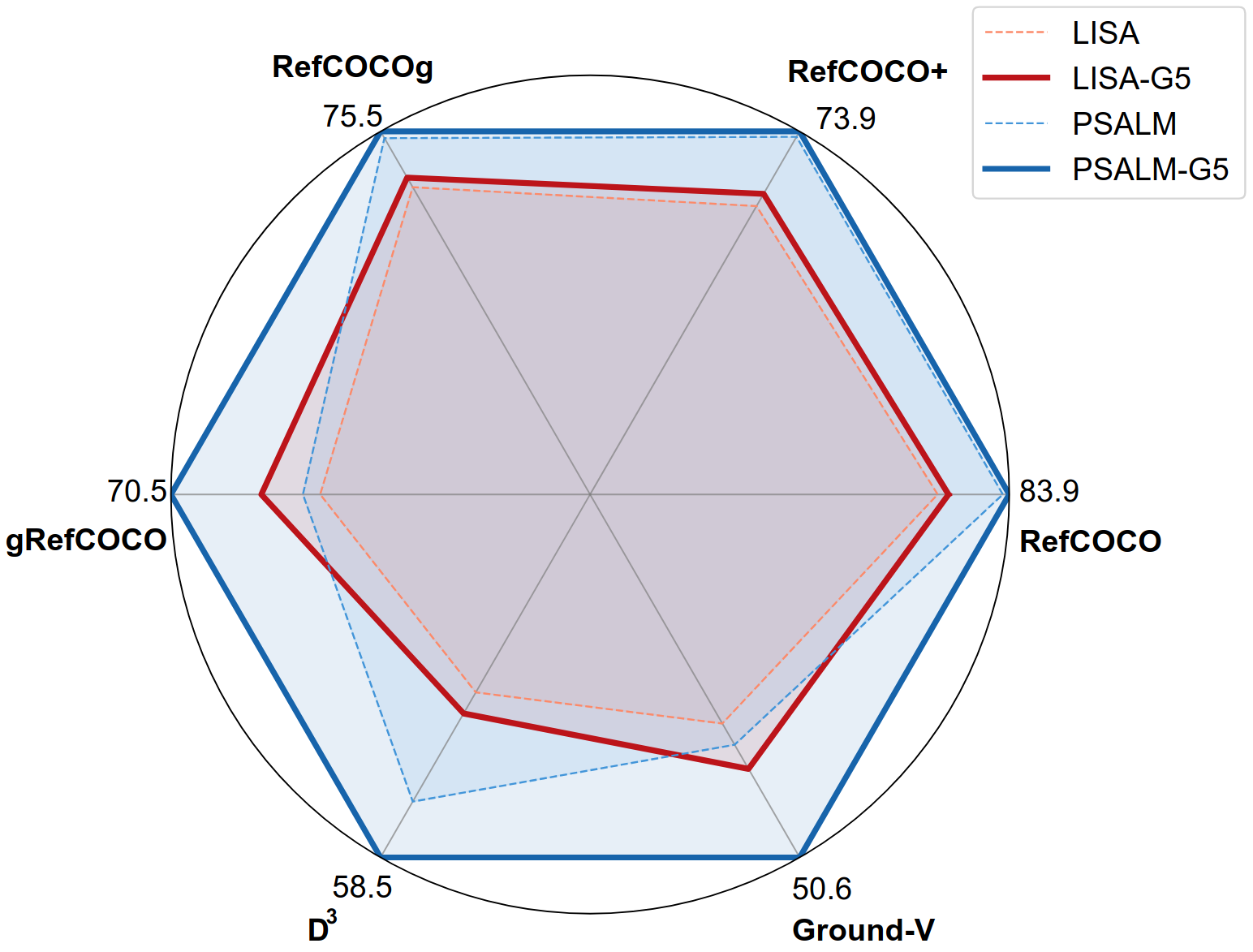 Ground-V: Teaching VLMs to Ground Complex Instructions in PixelsCVPR, 2025TL;DR: Ground-V sets new state-of-the-art on reasoning segmentation tasks.
Ground-V: Teaching VLMs to Ground Complex Instructions in PixelsCVPR, 2025TL;DR: Ground-V sets new state-of-the-art on reasoning segmentation tasks.







