Yongshuo Zong

EH8 9AB
Edinburgh, UK
I am a Research Scientist at Google Research. Previously, I did my PhD at the University of Edinburgh, supervised by Prof. Timothy Hospedales and Dr. Yongxin Yang, where I am funded by UKRI CDT in Biomedical AI. I obtained my BSc in computer science from Tongji University, in 2021.
I am broadly interested in machine learning and its applications in healthcare, especially with multi-modal learning and large vision-language models. Feel free to drop me an email for potential collaborations!
news
| Jan 08, 2026 | Passed my PhD viva! |
|---|---|
| Feb 26, 2025 | Ground-V from my internship at Amazon is accepted to CVPR’25! |
| Jan 22, 2025 | VL-ICL is accepted to ICLR’25! |
| Sep 03, 2024 | Start my internship at Amazon AWS AI! |
| Jul 11, 2024 | Survey on Self-supervised Multimodal Learning is accepted to IEEE T-PAMI! |
| May 01, 2024 | Both VLGuard and Fool your (V)LLMs are accepted to ICML’24! |
| Apr 24, 2024 | Giving a talk about VLGuard at BMVA Trustworthy Multimodal Foundation Models Symposium! |
| Feb 27, 2024 | C-VQA is accepted to CVPR’24! |
| Jan 17, 2024 | Giving a talk about Fool your (V)LLMs at BMVA Vision-Language Symposium! |
| Nov 06, 2023 | Invited talk about MEDFAIR at FAIMI workshop! |
| Feb 27, 2023 | Meta-Omnium is accepted to CVPR’23! |
| Jan 21, 2023 | MEDFAIR is accepted to ICLR’23 as spotlight! |
selected publications/preprints
-
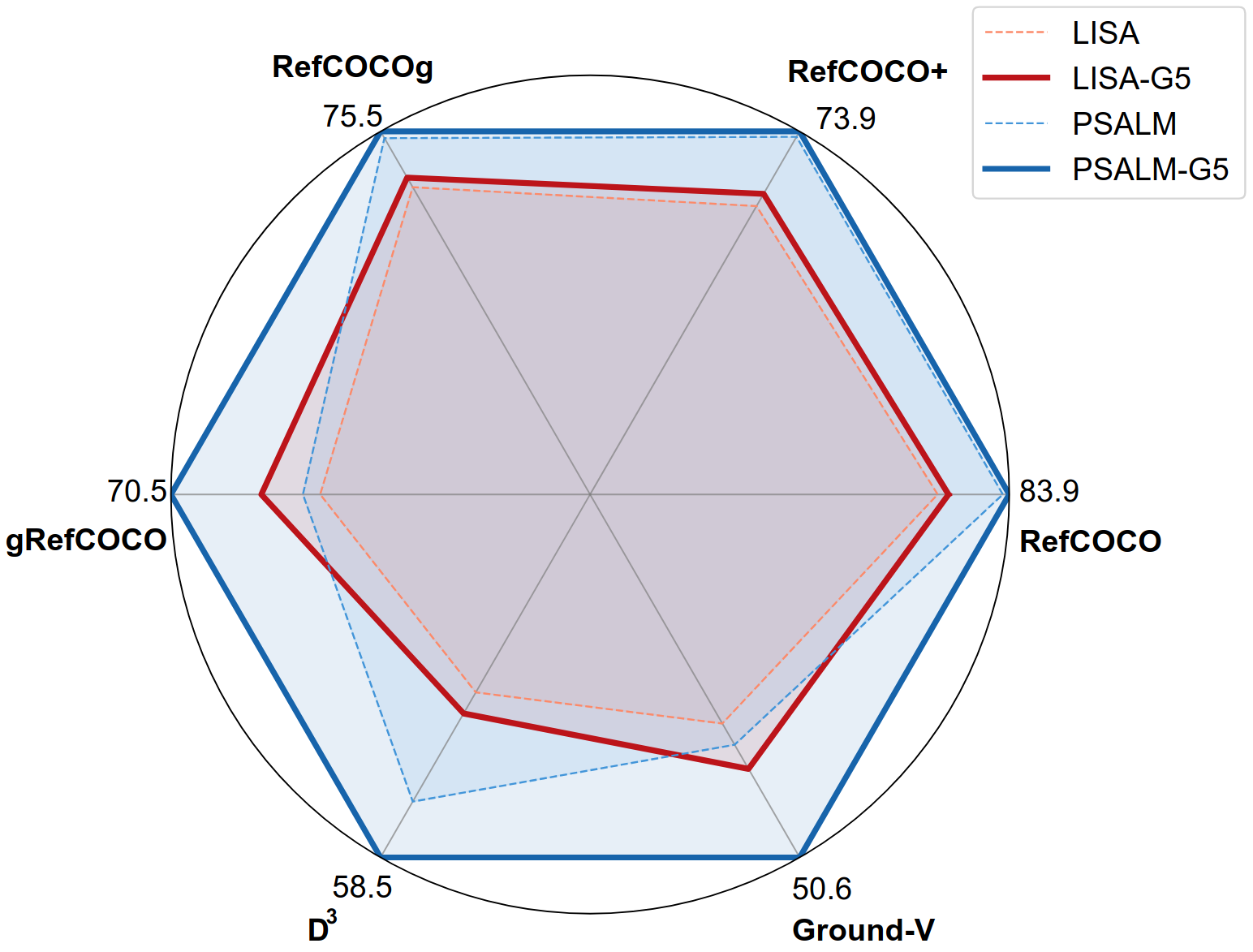 Ground-V: Teaching VLMs to Ground Complex Instructions in PixelsCVPR, 2025TL;DR: Ground-V sets new state-of-the-art on reasoning segmentation tasks.
Ground-V: Teaching VLMs to Ground Complex Instructions in PixelsCVPR, 2025TL;DR: Ground-V sets new state-of-the-art on reasoning segmentation tasks.








