Abstract
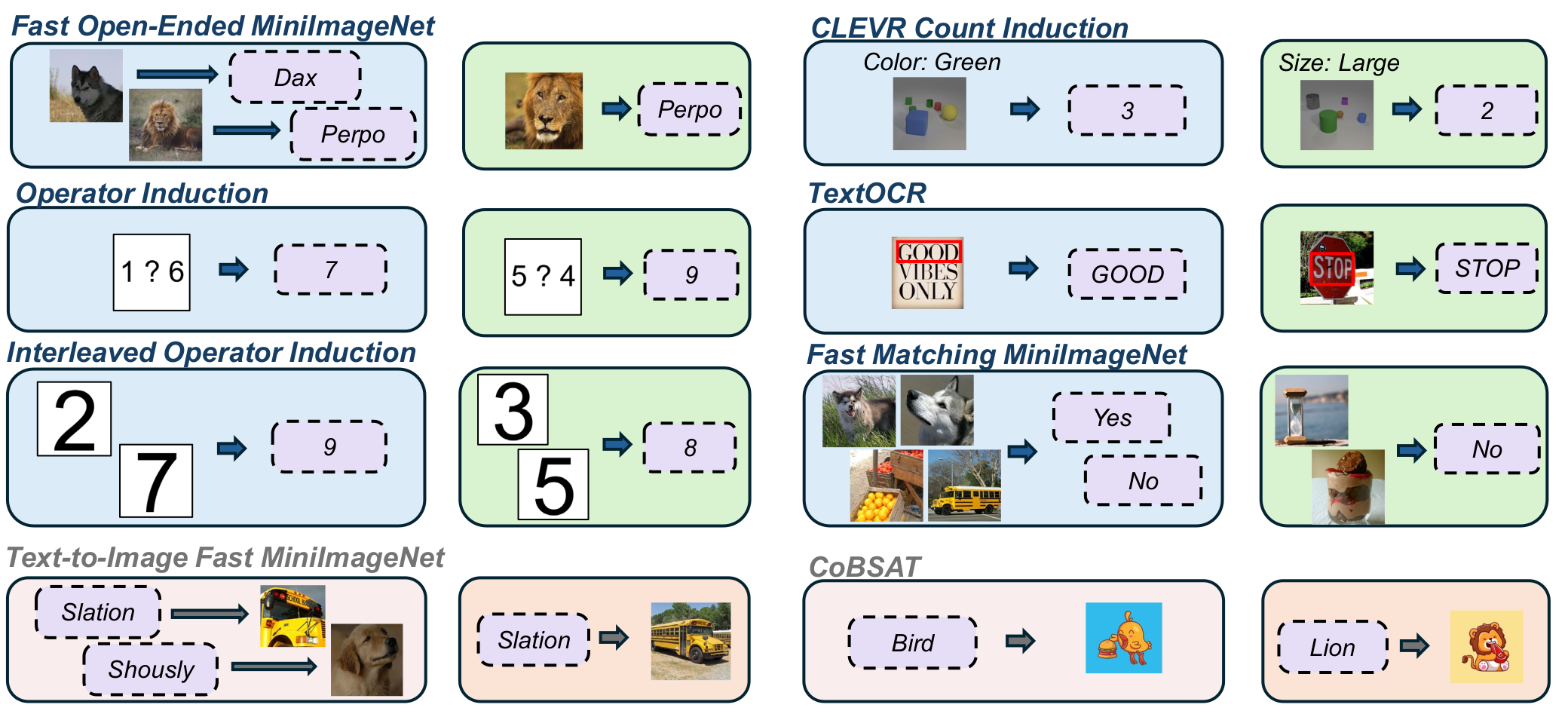
Figure: Illustration of the different tasks in VL-ICL Bench. Image-to-text tasks are in the first three rows, while text-to-image tasks are in the bottom two rows. Image-to-text tasks in the third row do reasoning on interleaved image-text inputs.
Contributions
- We demonstrate the limitations inherent in the common practice of quantitatively evaluating VLLM ICL via VQA and captioning.
- We introduce the first thorough and integrated benchmark suite of ICL tasks covering diverse challenges including perception, reasoning, rule-induction, long context-length and text-to-image/image-to-text.
- We rigorously evaluate a range of state-of-the-art VLLMs on our benchmark suite, and highlight their diverse strengths and weaknesses, as well the varying maturity of solutions to different ICL challenges.
VL-ICL Bench
Our VL-ICL Bench covers a number of tasks, which includes diverse ICL capabilities such as concept binding, reasoning or fine-grained perception. It covers both image-to-text and text-to- image generation. Our benchmark includes the following eight tasks: Fast Open MiniImageNet, CLEVR Count Induction, Operator Induction, Interleaved Operator Induction, TextOCR, Matching MiniImageNet, Text-to-image MiniImageNet and CoBSAT.
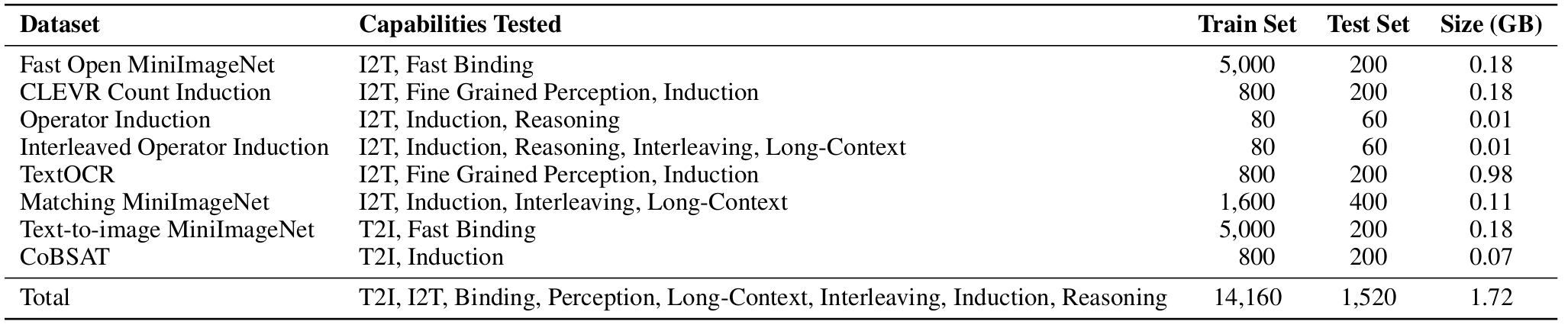
Table: VL-ICL Bench overview. It evaluates diverse capabilities and challenges of ICL with VLLMs. Meanwhile it is compact and easy to be used by researchers, without prohibitive resource requirements.
Results
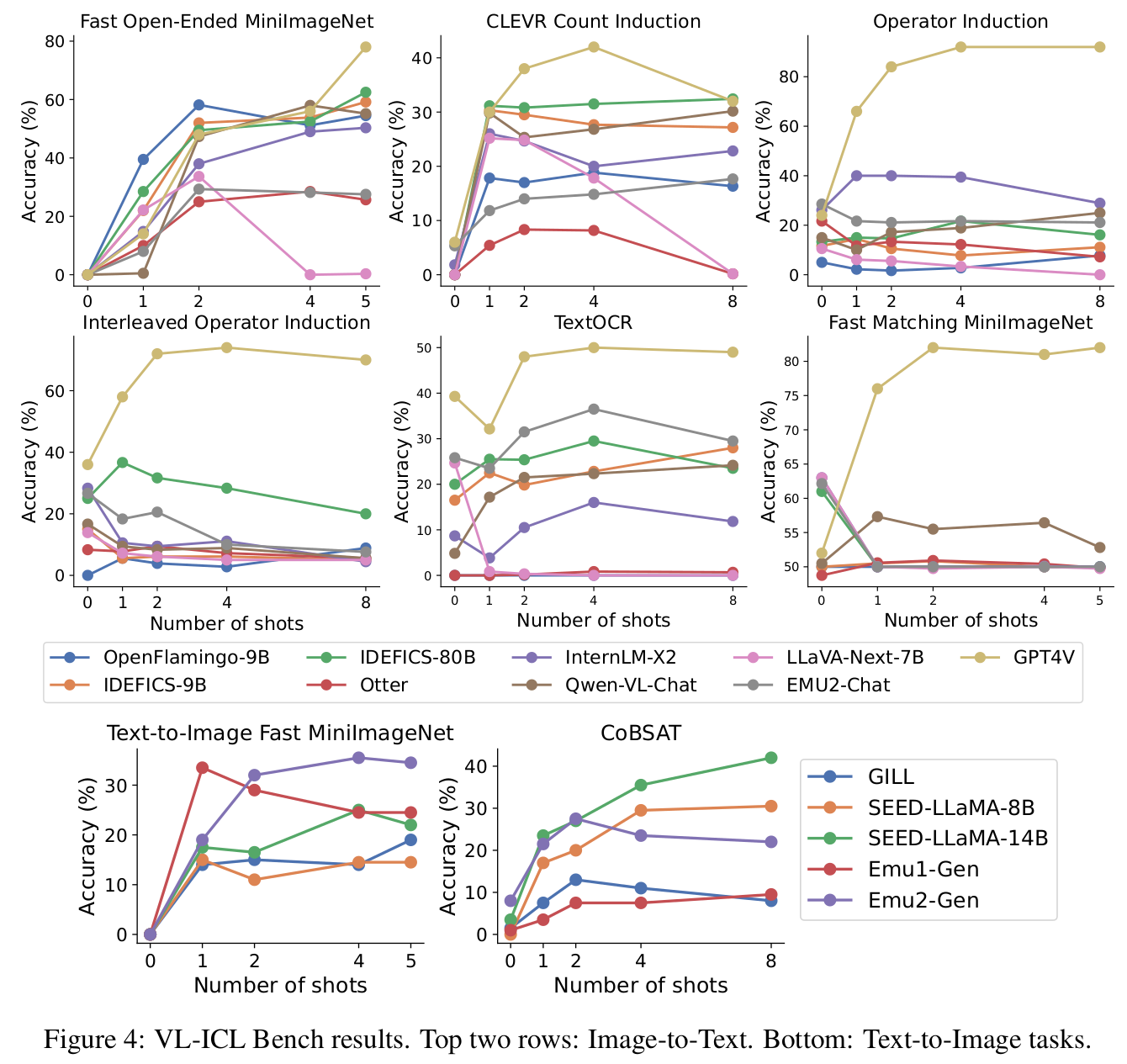 The main results for VL-ICL Bench are presented in the figure above including a breakdown over shots. We make the following observations:
The main results for VL-ICL Bench are presented in the figure above including a breakdown over shots. We make the following observations:
- VLLMs demonstrate non-trivial in-context learning on VL-ICL Bench tasks.
- VLLMs often struggle to make use of a larger number of ICL examples.
- GPT4V is the best overall image-to-text model.
- Zero-shot performance is not strongly indicative of ICL ability.
- There is No clear winner among text-to-image models.
Citation
@article{zong2024vlicl,
title={VL-ICL Bench: The Devil in the Details of Multimodal In-Context Learning},
author={Zong, Yongshuo and Bohdal, Ondrej and Hospedales, Timothy},
journal={arXiv preprint arXiv:2403.13164},
year={2024}
}