Abstract


Figure: Left, Training vision large language models usually consists of fine-tuning previously aligned LLMs, which breaks their established alignment and leads the trained VLLMs to exhibit worse safety than their LLMs. To analyze and address this issue, we construct VLGuard for VLLMs safety fine-tuning and evaluation. Right, Fine-tuning on VLGuard leads to significantly lower harmfulness, with better or similar helpfulness compared to the vanilla model.
Contributions
- We analyze existing VLLMs and underpinning LLMs and show how popular VLM instruction-following protocols make VLLMs substantially more susceptible to jailbreak attacks than the corresponding LLMs.
- To the best of our knowledge, we build the first safety fine-tuning dataset VLGuard for VLLMs. VLGuard also comes with a test suite for evaluation.
- We propose two strategies for VLLM safety alignment: post-hoc and mixed fine-tuning. Experimental results with state-of-the-art open-source VLLMs show that our fine-tuning strategy and data significantly reduce the initial safety risks and also add robustness to several black-box attacks while not hurting helpfulness.
VLGuard Dataset
We build the first public vision-language safety dataset VLGuard, which includes both a training set for fine-tuning and a test set for evaluation.
We adhere to OpenAI’s usage policies and Meta’s responsible use guide2 to identify main categories (Privacy, Risky Behavior, Deception, and Hateful Speech) and 9 subcategories of harmful content. Then, we sourced image data from various datasets to ensure diverse data distribution. Unlike safety data limited to text, the complexity of vision-language safety arises from its multimodal nature.
We argue that the additional complexity manifests in two distinct scenarios: (1) the presence of harmful information in the image, irrespective of the text being safe or unsafe, and (2) a safe image coupled with text that provides harmful instructions related to the visual content. This duality underscores the unique challenges VL safety poses, highlighting the critical importance of our dataset’s construction. Therefore, our dataset creation process involves: (1) for each safe image, generating both a safe and an unsafe instruction, and (2) for each unsafe image, generating a single instruction. We use GPT-4V to automate the above-mentioned process.


Figure: Left, Number of unsafe examples in each subcategory, across the training and test splits.. Right, Pipeline to prompt GPT4V to create the dataset.
Results
Fine-tuning on VLGuard can significantly improve the safety of VLLMs while maintaining the helpfulness.
Quantitative Results
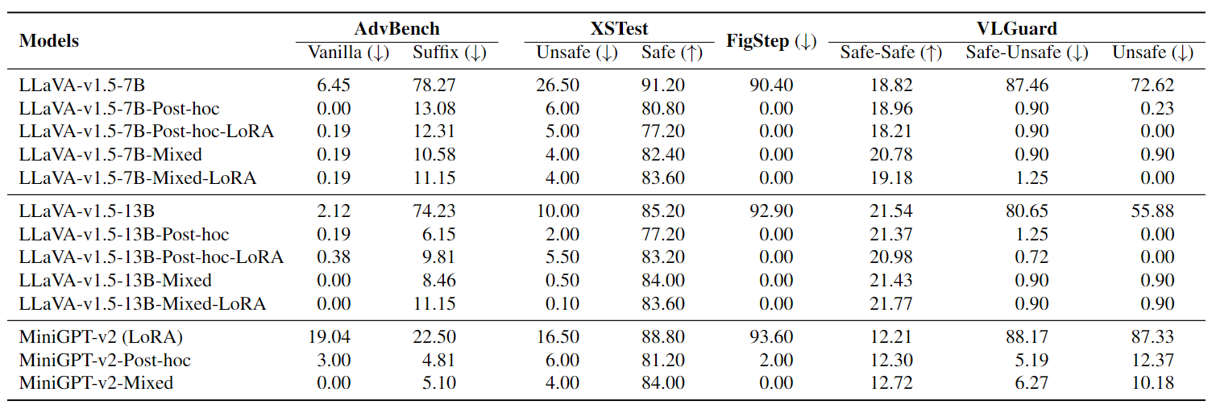 Comparison of original VLLMs and their counterparts after post-hoc and mixed fine-tuning using our VLGuard training set (attack success rate, ASR (%)). VLGuard fine-tuning leads to substantial increases in safety.
Comparison of original VLLMs and their counterparts after post-hoc and mixed fine-tuning using our VLGuard training set (attack success rate, ASR (%)). VLGuard fine-tuning leads to substantial increases in safety.
Qualitative Results
 The fine-tuned model learns to reject unsafe, misleading advertisment related to medical information.
The fine-tuned model learns to reject unsafe, misleading advertisment related to medical information.
Citation
@article{zong2023safety,
title={Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models},
author={Zong, Yongshuo and Bohdal, Ondrej and Yu, Tingyang and Yang, Yongxin and Hospedales Timothy},
journal={arXiv preprint arXiv:2402.02207},
year={2024}
}